프로젝트를 시작하기에 앞서 크롤링에 대한 정보와 지식을 얻으려 서칭을 했습니다.
크롤링이 법적 문제가 자주 일어나고 이를 침해하지않고 사용하는것이 중요다는것을 알게 되었다.
그래서 크롤링을 하기전에 알게된것에대해 다행이라고 생각했고 조심스럽게 사용해야겠다 생각하여 이것저것 찾아보았습니다.
그중 발견한것이 robots.txt 입니다.
robots.txt파일이란 웹크롤러와 같은 착한 로봇들의 행동들을 관리하는 것을 말합니다. 서비스를 제공하는 운영자는 이 로봇들을 관리해서 원하는 페이지를 노출이 되고 안되게 설정할 수 있고 저작권 침해를 방지할 수 있습니다.
robots.txt 기본 문법
– User-Agent: 웹사이트 관리자가 어떤 종류의 로봇이 크롤링을 하는지 알 수 있게합니다.
– Disallow: 이 명령은 어떤 웹페이지 URL을 크롤링 하지 않아야 하는지 알려준다.
– Allow: 모든 검색엔진이 이 명령을 인식하지는 않지만 특정 웹페이지나 디렉토리에 접근하라는 명령
– Crawl-delay: 검색엔진 스파이더 봇이 서버를 과도하게 사용하지 못하도록 대기하라는 명령
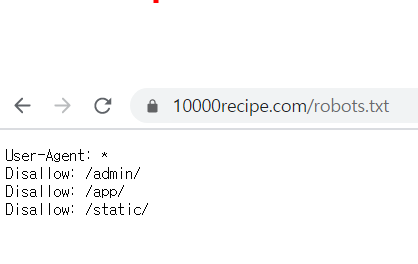
User-Agent: *
Disallow: /admin/
Disallow: /app/
Disallow: /static/확인한 결과 모든 User에게 admin, app, static만 disallow하고 있습니다.
이처럼 파일에 명시된 사항을 준수하면서 웹사이트의 컨텐츠를 수집해야 합니다.
크롤링을 하기전에 크롤링이 가능한 범위를 확인하고 사용할 필요가 있습니다.
'프로젝트 > 레시피추천 프로그램' 카테고리의 다른 글
| Mecab 형태소 분석기 dictionary 등록 (0) | 2021.01.05 |
|---|---|
| [데이터 전처리] 재료명 정확도 높이기 (0) | 2021.01.03 |
| [크롤링]- 메뉴와 재료 크롤링하기 (0) | 2021.01.03 |



