이전 포스팅에서는 전처리했던 내용을 포스팅하였습니다.
이 전처리 과정중에 단순히 mecab의 nouns함수를 이용하여 명사를 분류만 했었는데요 이 과정에서 불용어나 원치않는 단어가 많이 나왔었습니다.
그래서 이번에 제가 필요한대로 사전에 단어등록을 하고 우선순위를 수정했던 과정을 포스팅하려 합니다.
mecab설치와 사용법에 대한 자세한 내용은 다음 블로그를 참고하였습니다 :)
hong-yp-ml-records.tistory.com/91
[파이썬 NLP] Window에서 Mecab 사용하기 / Konlpy 토크나이저 비교
이번 포스팅은 Konlpy 라이브러리의 여러 토크나이저들과 그 성능을 비교해보는 시간을 가져보겠습니다! 또한 Konlpy와 별개로 추가 설치를 해야하는 Mecab 토크나이저의 설치 방법도 다뤄보도록
hong-yp-ml-records.tistory.com
바꿔주어야 할 요소
우선 mecab nouns를 적용하였을 때 결과를 보면
1. 미니단호박 -> 미니, 단호박
2. 피자치즈-> 피자, 치즈
3. 머스타드소스-> 머스타드, 소스
4. 부침가루-> 부침, 가루
이러한 경우들이 있습니다.
1번같은 경우는 '미니단호박'을 하나의 명사로 등록해도 되지만 단호박으로 통일하고 싶었기 때문에 '미니'를 불용어 처리하였습니다.
2번의 경우도 1번과 같은 경우지만 피자도 음식이라는 생각에 못 보고 넘어갈 뻔했습니다.. 피자를 재료로 사용하는 경우는 없으니까요. 그래서 이경우도 '피자치즈'를 단어로 등록하기보다 '피자'를 불용어 처리하였습니다
하지만 이경우에 문제가 생길 수 있습니다. 예를 들어 '피자소스'의 경우는 피자, 소스로 나뉠 텐데 피자를 불용어 처리하게 된다면 소스만 남게 됩니다. 그래서 피자소스를 mecab dictionary에 사전등록을 따로 해주어야 합니다.
3번은 재료명에 머스타드, 머스터드, 머스타드소스, 머스타트 등 외래어 표기가 다양하게 등록되어있는 경우였습니다.
이경우에는 전부 '머스타드'로 통일하였습니다. 이유는 레시피 재료로 머스타드는 정말 많이 들어가는데 이들을 표기하는 방법은 10가지 정도가 되었습니다. 이경우는 복잡하더라도 변환을 하여 데이터를 일정하게 가공해줄 필요가 있다 느꼈습니다.
그래서 소스를 불용어 처리하였고, mecab에는 '머스타드'만 사전등록이 되어있었지만 머스터드 등 다양한 표기법을 등록해주었습니다. (이방법외에도 함수를 작성해서 외래어들을 모두 머스타드로 문자열 변환해주어도 됩니다.)
마지막으로 4번의 경우에는 mecab의 dictionary등록이 제일 필요했던 부류의 단어였습니다.
부침가루는 하나의 재료로 필요한데 mecab은 '부침'과 '가루'를 각각의 명사로 등록되어있고 부침가루는 등록이 안되어있기 때문에 dictionary에 '부침가루'를 등록해주는 작업이 필요했습니다.
Mecab 사용자 dic 등록
사전 등록방법에 대한 포스팅은 다음 블로그를 참고하였습니다.
형태소 분석기 Mecab 사용하기 A to Z(설치부터 단어 우선순위 등록까지)
사전 사용이 까다로워서 정리해보고자 한다.
velog.io
우선 C:\mecab\user-dic 에 커스텀할 csv파일을 하나 만들어줍니다.
이후 custom.csv 엑셀 파일을 열어서 단어등록을 해줍니다.

이제 이 등록한 명사들이 mecab이 명사로 인식할 수 있도록 컴파일을 해줍니다.
powershell을 열고 $C:\mecab> tools\add-userdic-win.ps1 명령어를 입력하면 add-userdic-win.ps1이 사용자 사전등록을 하도록 컴파일해줍니다.
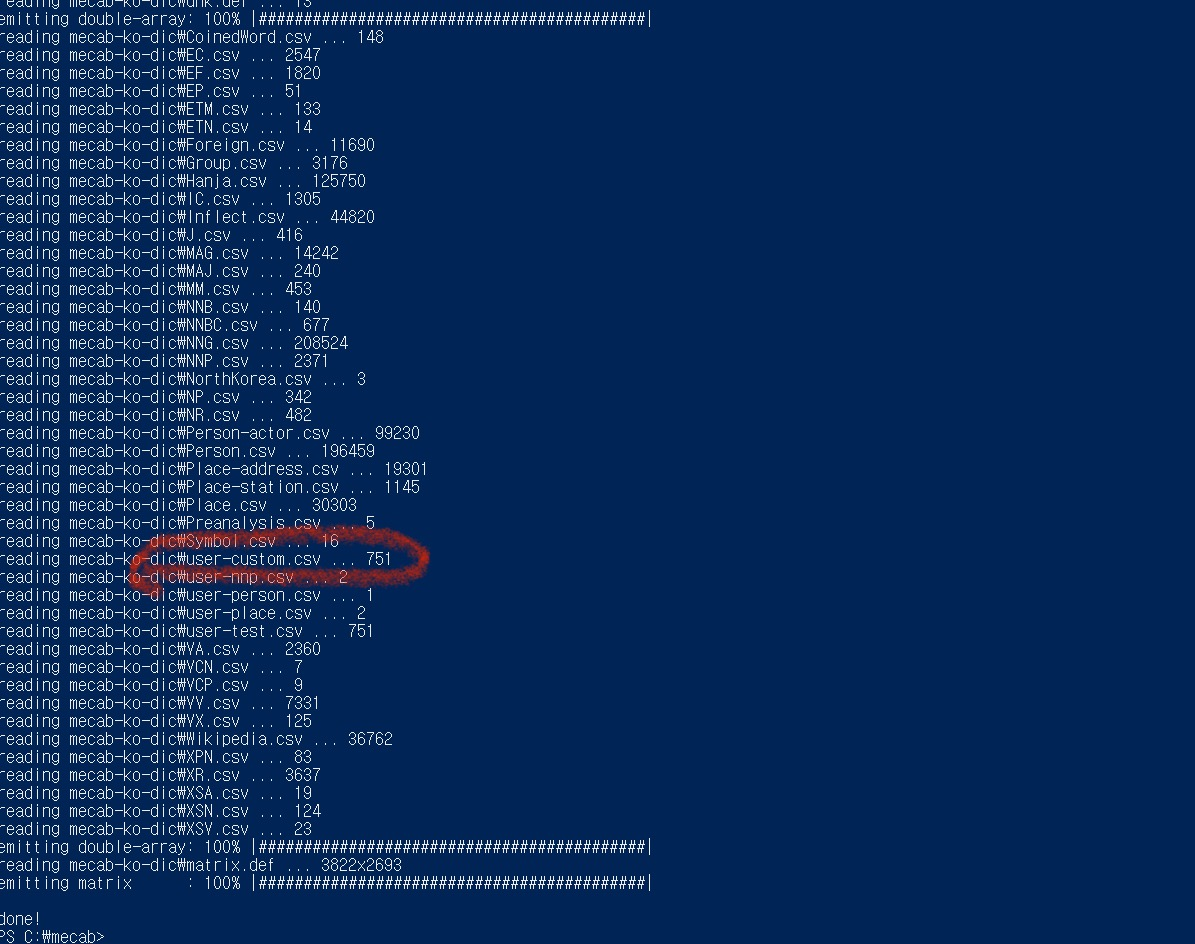
빨간색 선을 보면 custom.csv파일이 사전 등록되었음을 알 수 있습니다. (이외의 파일들은 mecab에 기본적으로 등록되어있는 파일들)
이제 잘 등록이 되었는지 확인해 보면


단어등록 이전과 비교해보면
더위, 사냥 -> 더위사냥
바, 밤, 바 -> 바밤바
로 변경된 것을 확인할 수 있습니다.
이처럼 성공적으로 원하는 대로 명사를 등록하며 정확도 높게 단어를 분류해 낼 수 있었습니다.
데이터 전처리 결론
crawling부터 데이터 가공 과정까지 아래와 같은 단계를 거쳤습니다.
1. BeautifulSoup을 이용하여 크롤링 후 파싱
2. 공백, 특수기호 제거
3. mecab을 이용하여 명사 처리( 우선순위, 사전등록 과정 거침)
4. 불용어 처리
5. 오타 단어, 중복 단어 제거
이 전처리 과정을 거치는 작업에 대해 처음이었지만 이 과정을 제대로 하지 않으면 word2vec학습에 안 좋은 결과를 미칠 수 있기 때문에 시간을 많이 투자하고 꼼꼼히 분류하였습니다.
힘들기도 했지만 분석하는 내내 깔끔하게 가공되어가는 데이터들을 보면 뿌듯하기도 하고 흥미로웠던 단계였습니다.
이제 이 전처리된 양질의 데이터를 이용하여 word2vec학습에 사용하는 포스팅을 올리도록 하겠습니다.
'프로젝트 > 레시피추천 프로그램' 카테고리의 다른 글
| [데이터 전처리] 재료명 정확도 높이기 (0) | 2021.01.03 |
|---|---|
| [크롤링]- 메뉴와 재료 크롤링하기 (0) | 2021.01.03 |
| 크롤링 접근 차단 robots.txt (0) | 2021.01.02 |



